基于全国产PCIE SWITCH 4.0/5.0的AI服务器PCIe拓扑应用研究 (一)
1 引言
为满足大数据、云计算和人工智能等领域的数
据收集与处理需求,采用各种异构形式的 AI服务
器得到了广泛应用。CPU+GPU 是 AI服务器中
普遍使用的计算单元组合[1]。其中,P2P(Peerto
Peer)通信用于多 GPU 系统中,借助缓存设备,可
以有效利 用 PCIe资 源 进 行 GPU 之 间 的 数 据 交
互[2]。
针对 GPU 加速应用,业内已有面向多种软件
工具、硬件配置和算法优化的研究。2016 年,Shi
等人[3]通过性能基准测试,比较了 GPU 加速深度
学习 的 软 件 工 具 (Caffe、CNTK、TensorFlow 和
Torch等);2018年,Xu等人[4]通过对软件和硬件
配置的组合研究,得到不同开源深度学习框架的应
用特性和功能,进一步量化了硬件属性对深度学习
工作 负 载 的 影 响;2019 年,Farshchi等 人[5]使 用
FireSim 将 开 源 深 度 神 经 网 络 加 速 器 NVDLA
(NVIDIA Deep Learning Accelerator)集 成 到
AmazonCloudFPGA 上的 RISC-VSoC 中,通过
运行 YOLOv3目标检测算法来评估 NVDLA 的性
能。但是,基于 CPU+GPU 架构,针对 AI服务器
在各应用场景中的分析却鲜有研究。
本文主要对 AI服务器中3种典型的 PCIe拓
扑 Balance Mode、Common Mode 和 Cascade
Mode的应用场景进行研究,旨在通过对3种拓扑
的点对点带宽与延迟、双精度浮点运算性能和深度
学习推理性能分析,得到3种拓扑在各应用场景中
的优势和劣势,为 AI服务器的实际应用提供优选
配置指导。
2 典型拓扑结构
2.1 3种基础拓扑结构
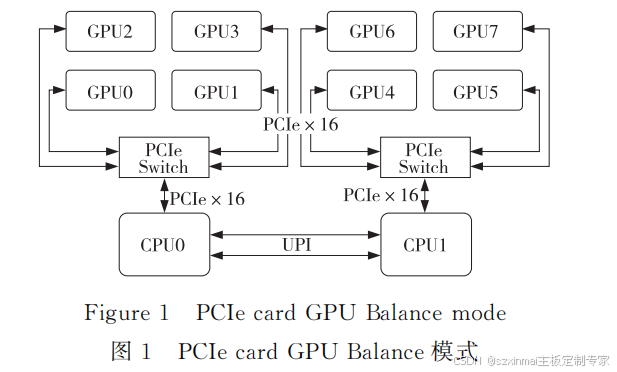
(1)BalanceMode。
BalanceMode拓扑为 Dualroot,根据PCIe资
源将 GPU 平 均 分 配 到 各 个 CPU,同 一 个 PCIe
Switch下的 GPU 可以实现 P2P 通信,不同 CPU
下挂接的 GPU 需要跨超级通道互联 UPI(Ultra
PathInterconnect)才能通信。以 8 个 GPU 卡为
例,BalanceMode拓扑结构如图1所示
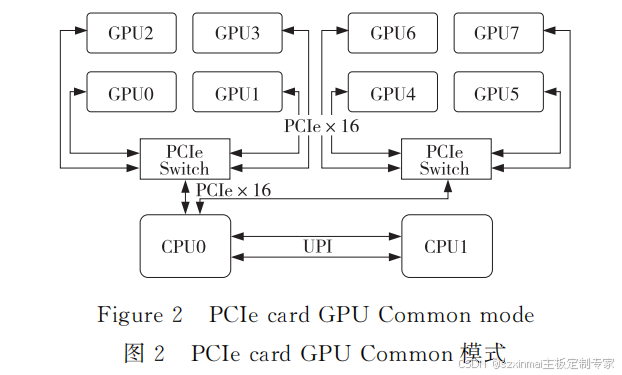
(2)CommonMode。
CommonMode拓扑中 GPU 的 PCIe资源均
来自同一个 CPU,同一个 PCIeSwitch下的 GPU
可以实现 P2P 通信,不同 PCIeSwitch 下挂接的
GPU 需要跨 CPU PCIeRootPort才能实现 P2P
通信,但通信带宽 低 于 同 一 个 PCIeSwitch 下 的
P2P通信。以 8 个 GPU 卡为例,Common Mode
拓扑结构如图2所示。
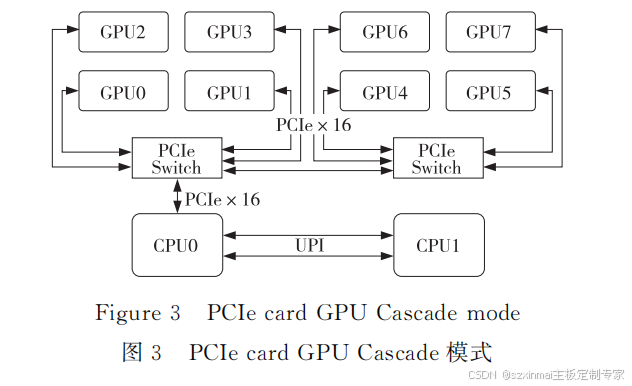
(3)CascadeMode。
CascadeMode拓扑中 GPU 的PCIe资源均来
自同一个 CPUPCIeRootPort,PCIeSwitch之间
为级联拓扑,同一级 PCIeSwitch下的 GPU 可以
实现 P2P通信,第1级 PCIeSwitch下的 GPU 和
第2级 PCIeSwitch下的 GPU 之间可以实现 P2P
通信,不需要通过 CPU PCIeRootPort。以8个
GPU 卡为 例,Cascade Mode拓 扑 结 构 如 图 3 所
示
全国产PCIE4.0/5.0 SWITCH NVMe 混合直连背板
*硬盘热插拔功能;
*灯态支持硬盘上电,读写,报错;
*SPGIO硬盘报错功能;
*硬盘分时启动;
*风扇温度控制;
* I2C(BMC);

