基于龙芯 2K1000处理器和复旦微 FPGA K7 的全国产RapidIO 解决方案研究
RapidIO 总线协议[1] 经过 20 多年的发展,已成为基
于数据分组交换的高性能系统互联[2] 首选解决方案之
一,广泛应用于无线通信、军事、超算、医学图像处理和
工业控制等多个领域,而这些领域无一例外地关系到国
计民生和国家安全。目前,提供 RapidIO 总线接口的芯
片主要来自美国恩智浦公司的 PowerPC、德州仪器公司
的 C6000系列 DSP、瑞萨公司的 TSI系列 RapidIO 交换芯
片和 PCIe 转 RapidIO 桥片,以及赛灵思公司的 RapidIO
IP 软 核,而 国 内 则 鲜 见 对 标 上 述 芯 片 的 国 产 化 替 代
方案。
本文提出一种基于龙芯 2K1000 处理器[3] 和复旦微
FPGA 的全国产 RapidIO 解决方案,并结合具体项目验
证该方案的可行性。
1 方案设计
1.1 总体设计
复杂的嵌入式设备,如核心网高端交换机、路由器、
5G 基站、飞机航电系统等,一般采用多子卡机架式设
计,这些子卡由机架背板布线信号联通,从而实现相互
间的通信。子卡间的通信一般包括数据平面通信和控
制平面通信。数据平面通信一般要求实现高可靠、高带
宽、低延迟的全双工通信,相应的数据平面系统互联方
案包括 RapidIO 总线、以太网和 PCIe 总线等,而 RapidIO
总线以其传输带宽高、互联信号线少、抗干扰性强、易于
扩展等优势成为如飞机航电系统等复杂系统的首选子
卡数据平面高速互联方案。
龙芯 2K1000 处理器(下文简称 CPU)是中科院计算
所研发的面向网络应用、工业控制等领域的嵌入式SoC处
理器。片内集成两个64位的双发射超标量GS264处理器
核,兼 容 MIPS64 体 系 结 构,主 频为 1 GHz,集 成 64 位
DDR3控制器、SATA3控制器、2个 x4的 PCIe 2.0控制器、
2 个千兆以太网控制器等多种外设。龙芯 2K1000 处理
器具有丰富的外设资源,适合作为控制子卡的处理器,但
由于片上没有集成 RapidIO 控制器,比较可行的替代方
案是使用复旦微JFM7K325T FPGA配合RapidIO IP软核
来实现RapidIO总线接口,再选取PCIe 2.0总线接口作为
龙芯 2K1000 处理器与复旦微 FPGA 之间交换数据的通
路。FPGA 端 RapidIO 总 线 采 用 LP⁃Serial x1 物 理 层 接
口,工作频率为 3.125 GHz,数据带宽为 2.5 Gb/s。软件
方面,在龙芯2K1000处理器上运行国产锐华实时操作系
统,并研发锐华系统下的 PCIe 驱动程序和 RapidIO 驱动
程 序;硬 件 方 面,使 用 中 航 通 用 公 司 自 行 研 发 的 国 产
RapidIOIP 软 核 。 以 龙 芯 2K1000 处 理 器 和 复 旦 微 电
JFM7K325T FPGA 为核心构建最小子系统,系统总体设
计方案[4] 如图1所示。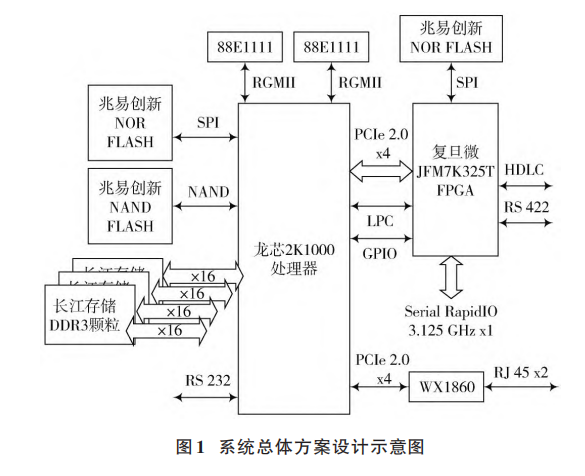
CPU 与 FPGA 之间通过 PCIe 总线和 LPC 总线相连,
其中高速信号使用 PCIe 总线传输,控制信号使用 LPC
总 线 传 输。RapidIO 差 分 信 号 由 FPGA 引 出。CPU 和
FPGA 均使用基于 SPI 总线的 NOR FLASH 存储启动固
件,CPU 的大容量文件存储使用并行的 Nand FLASH,
CPU 外接 4 片 x16 的国产 DDR3 颗粒,CPU 片上集成的
两 路 GMAC 以 太 网 控 制 器 通 过 RGMII 接 口 外 接
88E1111 千兆以太网 PHY。FPGA 除引出 RapidIO 信号
外,还实现了 HDLC 同步串口信号和 RS 422 高速串口
信号。子系统的外围均使用国产化芯片,例如兆易创
新 公 司 研 发 的 FLASH 芯 片 、长 江 存 储 公 司 研 发 的
DDR3 芯片和中电 32 所研发的 88E1111 以太网 PHY 芯
片等。
1.2
数据传输
FPGA 与 CPU 之间通过 PCIe 总线[5] 交换数据的方式
主要有两种,分别是 PIO 方式和 DMA 方式。PIO 方式的
原理是:FPGA 在 PCIe BAR 区间划出一定范围,实现数
据寄存器、控制寄存器和状态寄存器,CPU 使用 MMU 映
射 PCIe BAR 空间,并基于简单的数据拷贝算法实现数
据交换[6] 。使用 PIO 方式进行 PCIe 数据传输时,CPU 每
次读、写数据寄存器都会触发 PCIe 的 TLP 事务包,当数
据 寄 存 器 为 4 B 时 ,净 荷 数 据 只 占 到 TLP 事 务 包 的
4 256,加上 PCIe 每次 TLP 事务建立开销,容易得出 PIO
方式效率低的结论,因此不适合作为高速 RapidIO 总线
的数据通路。
DMA 方式使用 FPGA 中的 DMA 通道,在 CPU 内存
和 FPGA 内存间搬运数据,每次搬运时尽可能保证 TLP
事务包中的净荷数据最大,且搬运过程不需要 CPU 参
与。当 CPU 向 FPGA 发送数据时,CPU 仅向 FPGA 告知
需要发送数据的地址和长度,由 DMA 通道负责搬运数
据,数据搬运完成后,FPGA 以 PCIe MSI 中断的异步方
式 通 知 CPU 数 据 搬 运 完 成;当 CPU 从 FPGA 接 收 数 据
时,CPU 首先告知 FPGA 写入数据的内存地址,当 FPGA
数据就绪时,DMA 通道将数据搬运到该内存地址中,然
后向 CPU 发送 PCIe MSI 中断,通知 CPU 数据搬运完成,
CPU 可以通过读取 FPGA 特定的寄存器来获取搬运数
据的实际长度。
本方案采纳的是一种改进的 XDMA 方式[7] ,该方法
的 核 心 思 想 是 使 用 数 据 描 述 符 链 表 来 控 制 CPU 与
FPGA 之间的 PCIe 数据收发与同步。XDMA 数据描述
符如图 2 所示,数据描述的长度为固定的 32 B,存储数
据描述符的缓冲区地址要保持与 CPU 缓存行对齐,保
证内存吞吐效率最优。描述符中存储了 DMA 通道需要
搬运数据的长度、数据的源地址(从 CPU 向 FPGA 搬运
数据时使用)/目的地址(从 FPGA 向 CPU 搬运数据时使
用);控制字字段包括数据搬运完成标志位,用于标识数
据搬运的状态。描述符之间通过下一个相邻描述符地
址字段连接成单向链表,链表中最后一个描述符的该字
段为空,作为链表尾部标识。CPU 在接收和发送数据前
按需准备好数据描述符链表,并把链表首个描述符的地
址设置到 FPGA 的 XDMA 寄存器中。
信迈提供龙芯+FPGA国产化解决方案。